GPT-5.4 到底变强了多少?三大核心能力+电脑操控Codex上手实测!
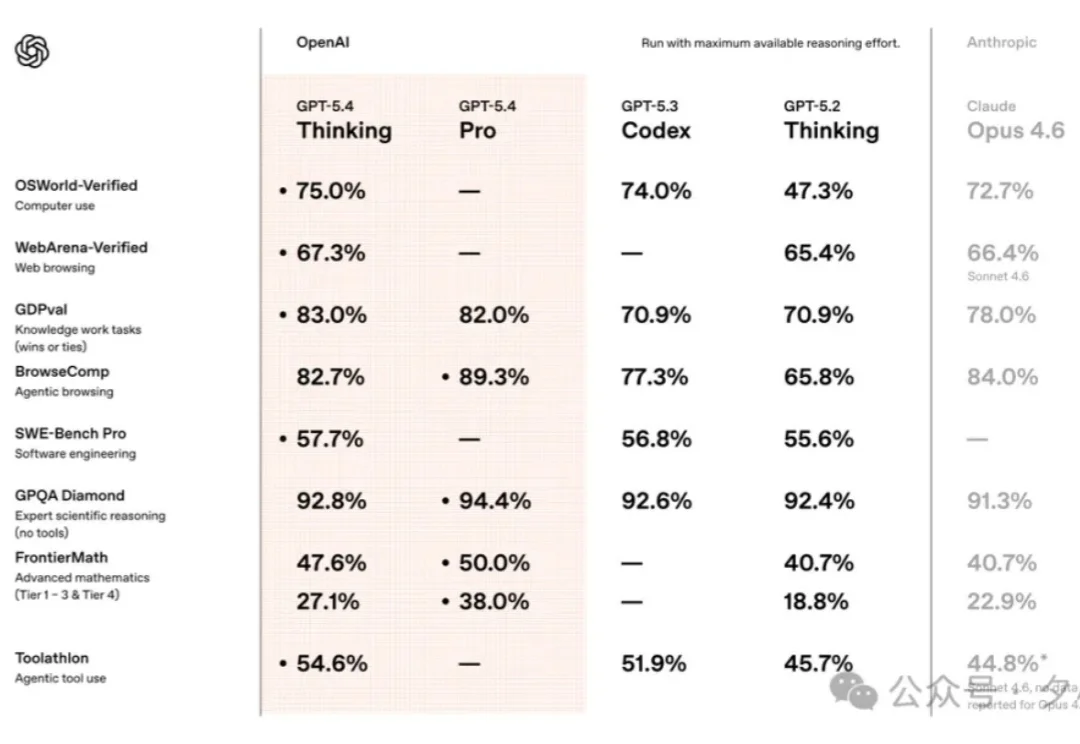
GPT-5.4 到底变强了多少?三大核心能力+电脑操控Codex上手实测!上周,GPT-5.4 发了。意图非常明显,直指 Claude Opus4.6 和 Gemini 3.1 Pro。
来自主题: AI产品测评
7926 点击 2026-03-10 10:00
 搜索
搜索
上周,GPT-5.4 发了。意图非常明显,直指 Claude Opus4.6 和 Gemini 3.1 Pro。

近日,Anthropic 公布了一组惊人的数字,在与 Mozilla 公司进行合作,测试旗下模型 Claude Opus 4.6 发现漏洞能力的过程中,两周内,就找出 Mozilla 公司「火狐」(Firefox)浏览器中 22 个不同的漏洞,其中 14 个是「高危漏洞」级别,而这几乎是 Mozilla 2025 年修复的全部「高危漏洞」的五分之一。
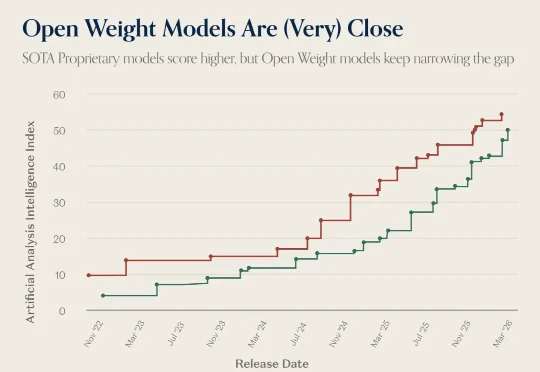
a16z 昨天发了一张图,把 GLM-5 和 Claude Opus 4.6 并排标注在 Artificial Analysis Intelligence Index 的时间线上。原文的说法是: A proprietary model (Claude Opus 4.6) is still the 'most intelligent,' but the gap between
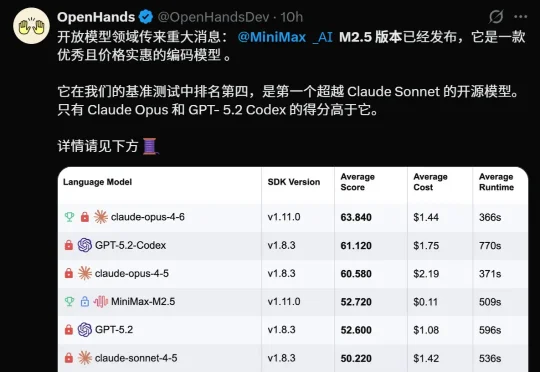
开源模型新王 MiniMax M2.5 震撼降临:M2.5 编码性能逼平 Claude Opus 4.6,价格却只有 1/20;1 美金 / 小时,这种尺寸和性能的模型,才能在算力短缺的时代不降智不卡顿,持续提供最好体验,成为最终王者!
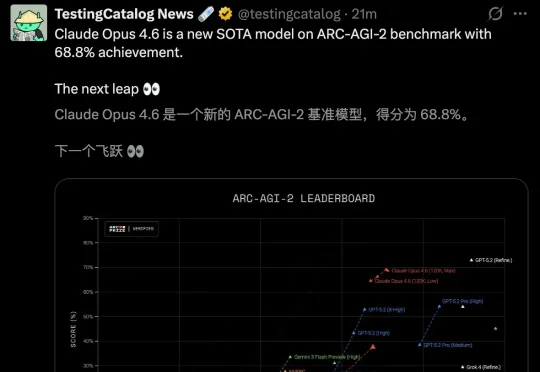
整个硅谷又癫狂了!Anthropic深夜扔出王炸,Claude 4.6用近乎恐怖的编程能力和智能体军团,给OpenAI和谷歌上了一堂名为「降维打击」的课。
最近两周的模型竞赛非常热闹:OpenAI 在 11 月 12 日发布 GPT-5.1,引入更强的推理深度与更高效的对话体验;Google 在 11 月 18 日发布 Gemini 3,全面强化多模态理解与复杂推理能力;Anthropic 在 11 月 24 日又发布了 Claude Opus 4.5,模型在专业文档处理、代码生成与长流程 agent 方面有显著提升。
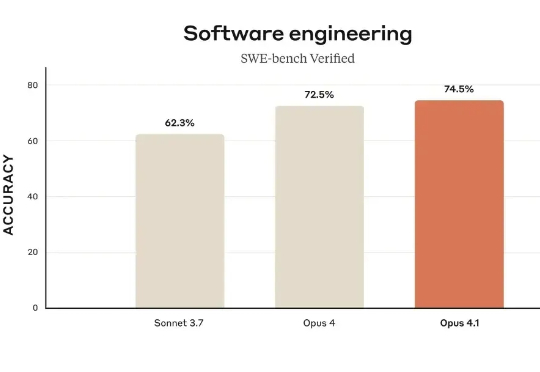
一直以来,Anthropic 的 Claude 被认为是处理编程任务的最佳模型,尤其是本月初发布的 Claude Opus 4.1,在真实世界编程、智能体以及推理任务上表现出色。其中在软件编程权威基准 SWE-bench Verified 测试中,Claude Opus 4.1 相较于前代 Opus 4 又有提升,尤其在多文件代码重构方面表现出显著进步。
OpenAI 发布了 GPT-5,我在公众号里、社群里、论坛里,很多地方都在刷屏一个消息:GPT-5 来了,而且在编程能力上“强得可怕”。
你会掏钱吗?你说巧不巧,就在 Sam Altman 官宣两个开源推理模型之前的半个小时,却被 Anthropic 抢先一步,发布了新模型 Claude Opus 4.1。
GPT-5又咕咕,但是把Claude新模型诈了出来—— Claude Opus 4.1,被曝正在进行内部测试。